
1 MyBatis Plus 简介
Mybatis-Plus(简称MP)是一个 Mybatis 的增强工具,在 Mybatis 的基础上只做增强不做改变,为简化开发、提高效率而生。
谁适合阅读本教程?
本教程适合所有学习过 mybatis(能熟练使用 mybatis,否则体会不到它的方便和高效),但是需要对 mybatis-plus 了解和应用的同学。
特性
· 无侵入:只做增强不做改变,引入它不会对现有工程产生影响,如丝般顺滑
· 损耗小:启动即会自动注入基本 CURD,性能基本无损耗,直接面向对象操作
· 强大的 CRUD 操作:内置通用 Mapper、通用 Service,仅仅通过少量配置即可实现单表大部分 CRUD 操作,更有强大的条件构造器,满足各类使用需求
· 支持主键自动生成:支持多达 4 种主键策略(内含分布式唯一 ID 生成器 - Sequence),可自由配置,完美解决主键问题
· 内置代码生成器:采用代码或者 Maven 插件可快速生成 Mapper 、 Model 、 Service 、 Controller 层代码,支持模板引擎,更有超多自定义配置等您来使用
· 内置分页插件:基于 MyBatis 物理分页,开发者无需关心具体操作,配置好插件之后,写分页等同于普通 List 查询
· 分页插件支持多种数据库:支持 MySQL、MariaDB、Oracle、DB2、H2、HSQL、SQLite、Postgre、SQLServer 等多种数据库
mybatis plus中实现对象封装操作类,他的层级关系如下:
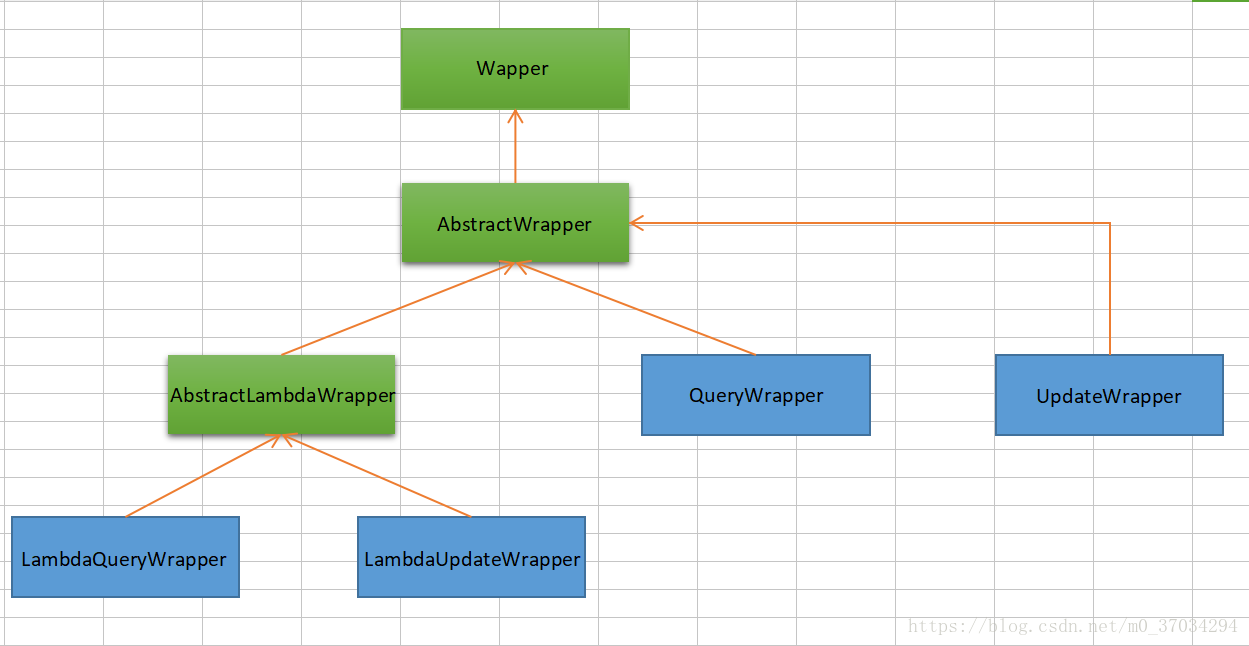
Wrapper : 条件构造抽象类,最顶端父类,抽象类中提供4个方法西面贴源码展示
AbstractWrapper : 用于查询条件封装,生成 sql 的 where 条件
AbstractLambdaWrapper : Lambda 语法使用 Wrapper统一处理解析 lambda 获取 column。
LambdaQueryWrapper :看名称也能明白就是用于Lambda语法使用的查询Wrapper
LambdaUpdateWrapper : Lambda 更新封装Wrapper
QueryWrapper : Entity 对象封装操作类,不是用lambda语法
UpdateWrapper : Update 条件封装,用于Entity对象更新操作
2 环境搭建
1 导入依赖
1 | <!--mybatis-plus依赖--> |
2 配置数据源和sql,sql打印, 映射文件配置
1 | spring.datasource.driver-class-name=com.mysql.jdbc.Driver |
3 BaseMapper 接口简介
课堂演示 数据表的表结构
DROP TABLE IF EXISTS user_info;
CREATE TABLE user_info (
user_id int(11) NOT NULL auto_increment,
user_name varchar(40) default NULL,
user_pwd varchar(40) default NULL,
user_detail_id int(11) default NULL,
PRIMARY KEY (user_id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
定义pojo 类
1 |
|
1 @TableName 注解用来将指定的数据库表和 JavaBean 进行映射。
2 @TableId 注解的用法,该注解用于将某个成员变量指定为数据表主键.
value指定数据表主键字段名称,不是必填的,默认为空字符串
type 指定数据表主键类型,如:ID自 增、UUID等。该属性的值是一个 IdType 枚举类型,默认为 IdType.NONE。
AUTO 数据库 ID 自增。如果我们创建数据库表时使用了 AUTO_INCREMENT 修饰主键
3 @TableField 字段注解,该注解用于标识非主键的字段。将数据库列与 JavaBean 中的属性进行映射,例如:
exist 是否为数据库表字段,默认为 true。
定义BaseMapper接口
例如:
1 | public interface UserInfoMapper extends BaseMapper<UserInfo> { |
你会发现,我们在 UserInfoMapper中没有声明任何方法。但是我们在 UserInfoMapper测试类中却使用了 insert()、selectById()、updateById() 和 deleteById() 方法。而这些方法均来至 BaseMapper 接口
Insert保存数据
1 | //insert新增 |
Update修改数据
1 | //根据id修改 |
Delete删除数据
1 | //根据id删除 |
Select查询数据
根据id查询
1 | //根据id查询 |
Wrapper 查询且只返回一条记录
1 | //根据 Wrapper 查询,且只返回一条记录 |
Wrapper 查询且只返回多条记录
1 | //根据 Wrapper 查询,返回多条记录 |
批量查询
1 | //批量查询 |
动态查询
1 | //动态查询 |
分页查询
1 | //分页查询 |
排序查询
1 | //排序查询 |
一对一分页查询
1 | 需求:完成一对一查询,userinfo用户表和userdetail用户详细信息表是一对一关系 |
一对多分页查询
1 | 需求:完成一对多分页查询,userinfo用户表和userLog用户日志表是一对多关系, |
4 条件构造器

本章节将介绍 eq(等于)和 ne(不等于)判断条件。
eq(等于 =)
1 | eq(R column, ``Object` `val)``eq(``boolean` `condition, R column, ``Object` `val) |
实例: 过滤 name 等于“张三”的用户信息
1 | QueryWrapper<UserBean> wrapper = ``new` `QueryWrapper<>();``wrapper.eq(``"name"``, ``"张三"``); ``// 等价 SQL 语句:name = '张三' |
ne(不等于 != 或 <>)
1 | ne(R column, ``Object` `val)``ne(``boolean` `condition, R column, ``Object` `val) |
实例:查询 name 不等于“张三”的用户信息
1 | QueryWrapper<UserBean> wrapper = ``new` `QueryWrapper<>();``wrapper.ne(``"name"``, ``"张三"``);``// 等价的 SQL 语句: 或 name != '张三' |
参数说明:
- column:要用于条件筛选的数据库表列名称,如:name
- val:用于指定数据表列的值,条件将根据该值进行筛选
- condition:用于指定当前这个条件是否有效;如果为 true,则应用当前条件;如果为 false,则忽略当前条件。
gt(大于 >)
1 | gt(R column, ``Object` `val)``gt(``boolean` `condition, R column, ``Object` `val) |
实例:查询 age 大于 18 岁
1 | QueryWrapper<UserBean> wrapper = ``new` `QueryWrapper<>();``wrapper.gt(``"age"``, ``18``); ``// 等价 SQL 语句:age > 18 |
ge(大于等于 >=)
1 | ge(R column, ``Object` `val)``ge(``boolean` `condition, R column, ``Object` `val) |
实例:查询 age 大于等于 18 岁
1 | QueryWrapper<UserBean> wrapper = ``new` `QueryWrapper<>();``wrapper.ge(``"age"``, ``18``); ``// 等价 SQL 语句:age >= 18 |
lt(小于 <)
1 | lt(R column, ``Object` `val)``lt(``boolean` `condition, R column, ``Object` `val) |
实例:查询 age 小于 18 岁
1 | QueryWrapper<UserBean> wrapper = ``new` `QueryWrapper<>();``wrapper.lt(``"age"``, ``18``); ``// 等价 SQL 语句:age < 18 |
le(小于等于 <=)
1 | le(R column, ``Object` `val)``le(``boolean` `condition, R column, ``Object` `val) |
实例:查询 age 小于等于 18 岁
1 | QueryWrapper<UserBean> wrapper = ``new` `QueryWrapper<>();``wrapper.le(``"age"``, ``18``); ``// 等价的 SQL 语句:age <= 18 |
参数说明:
- column:要用于条件筛选的数据库表列名称,如:name
- val:用于指定数据表列的值,条件将根据该值进行筛选
- condition:用于指定当前这个条件是否有效;如果为 true,则应用当前条件;如果为 false,则忽略当前条件
like(完全模糊,即“like ‘%val%’”)
1 | like(R column, ``Object` `val)``like(``boolean` `condition, R column, ``Object` `val) |
参数说明:
- column:要用于条件筛选的数据库表列名称,如:name
- val:用于指定数据表列的值,条件将根据该值进行筛选
- condition:用于指定当前这个条件是否有效;如果为 true,则应用当前条件;如果为 false,则忽略当前条件。
实例:查询用户名称中包含“王”值的用户信息,如下:
1 | QueryWrapper<UserBean> wrapper = ``new` `QueryWrapper<>();``wrapper.like(``"name"``, ``"王"``); ``// 等价 SQL 语句:name like '%王%' |
notLike(完全模糊取非,即“not like ‘%val%’”)
1 | notLike(R column, ``Object` `val)``notLike(``boolean` `condition, R column, ``Object` `val) |
参数说明:
- column:要用于条件筛选的数据库表列名称,如:name
- val:用于指定数据表列的值,条件将根据该值进行筛选
- condition:用于指定当前这个条件是否有效;如果为 true,则应用当前条件;如果为 false,则忽略当前条件。
实例:查询用户包含“王”值的用户信息,如下:
1 | QueryWrapper<UserBean> wrapper = ``new` `QueryWrapper<>();``wrapper.notLike(``"name"``, ``"王"``); ``// 等价 SQL 语句:name not like '%王%' |
likeLeft(仅左边模糊,即“like ‘%val’”)
1 | likeLeft(R column, ``Object` `val)``likeLeft(``boolean` `condition, R column, ``Object` `val) |
参数说明:
- column:要用于条件筛选的数据库表列名称,如:name
- val:用于指定数据表列的值,条件将根据该值进行筛选
- condition:用于指定当前这个条件是否有效;如果为 true,则应用当前条件;如果为 false,则忽略当前条件。
实例:查询用户名以“王”值结束的用户信息列表,如下:
1 | QueryWrapper<UserBean> wrapper = ``new` `QueryWrapper<>();``wrapper.likeLeft(``"name"``, ``"王"``); ``// 等价 SQL 语句:name like '%王' |
likeRight(仅右边模糊,即“like ‘val%’”)
1 | likeRight(R column, ``Object` `val)``wrapper.likeRight(``boolean` `condition, R column, ``Object` `val) |
参数说明:
- column:要用于条件筛选的数据库表列名称,如:name
- val:用于指定数据表列的值,条件将根据该值进行筛选
- condition:用于指定当前这个条件是否有效;如果为 true,则应用当前条件;如果为 false,则忽略当前条件。
实例:查询用户名以“王”值开始的用户信息列表,如下:
1 | QueryWrapper<UserBean> wrapper = ``new` `QueryWrapper<>();``likeRight(``"name"``, ``"王"``); ``// 等价 SQL 语句:name like '王%' |
isNull(字段 IS NULL)
1 | isNull(R column)``isNull(``boolean` `condition, R column) |
参数说明:
- column:字段名
- condition:用于指定当前这个条件是否有效;如果为 true,则应用当前条件;如果为 false,则忽略当前条件。
isNotNull(字段 IS NOT NULL)
1 | isNotNull(R column)``isNotNull(``boolean` `condition, R column) |
参数说明:
- column:字段名
- condition:用于指定当前这个条件是否有效;如果为 true,则应用当前条件;如果为 false,则忽略当前条件。
实例:构造 name 为空,或者 name 不为空的查询条件,如下:
1 | QueryWrapper<UserBean> wrapper = new QueryWrapper<>();wrapper.isNull("name"); // 等价 SQL 语句:name is null` |
orderByAsc(实现递增排序)
1 | orderByAsc(R... columns)``orderByAsc(``boolean` `condition, R... columns) |
参数说明:
- columns:列名称,可以指定多个
- condition:用于指定当前这个条件是否有效;如果为 true,则应用当前条件;如果为 false,则忽略当前条件
实例:根据用户 ID 和 年龄递增排序。
1 | QueryWrapper<UserBean> wrapper = ``new` `QueryWrapper<>();``wrapper.orderByAsc(``"user_id"``, ``"age"``); |
orderByDesc(实现递减排序)
1 | orderByDesc(R... columns)``orderByDesc(``boolean` `condition, R... columns) |
参数说明:
- columns:列名称,可以指定多个
- condition:用于指定当前这个条件是否有效;如果为 true,则应用当前条件;如果为 false,则忽略当前条件
实例:根据用户 ID 和 年龄递减排序。
1 | QueryWrapper<UserBean> wrapper = ``new` `QueryWrapper<>();``wrapper.orderByDesc(``"user_id"``, ``"age"``); |
orderBy(自定义排序方式)
1 | orderBy(``boolean` `condition, ``boolean` `isAsc, R... columns) |
参数说明:
- columns:列名称,可以指定多个
- condition:用于指定当前这个条件是否有效;如果为 true,则应用当前条件;如果为 false,则忽略当前条件
- isAsc:是否使用 ASC 排序,即递增排序;否则,则使用递减(DESC)排序
实例:根据用户 ID 和 年龄递减排序。
1 | QueryWrapper<UserBean> wrapper = ``new` `QueryWrappe |
group by 分组
groupBy 实现分组,groupBy 函数定义如下:
1 | groupBy(R... columns)``groupBy(``boolean` `condition, R... columns) |
参数说明:
- columns:要分组的数据表列名称列表
- condition:用于指定当前这个条件是否有效;如果为 true,则应用当前条件;如果为 false,则忽略当前条件。
实例:用户信息表根据 sex 和 age 列进行分组,如下:
1 | QueryWrapper<UserBean> wrapper = ``new` `QueryWrapper<>();``wrapper.groupBy(``"sex"``, ``"age"``); |
运行上面代码,你实际上将执行如下 SQL 语句:
1 | SELECT` `user_id,``name``,sex,age,face,salary,borthday ``FROM` `user` `GROUP` `BY` `sex,age |
or(或,拼接SQL的 OR 语句)
1 | or()``or(``boolean` `condition) |
参数说明:
- condition:用于指定当前这个条件是否有效;如果为 true,则应用当前条件;如果为 false,则忽略当前条件。
注意:主动调用 or 表示紧接着下一个方法不是用 and 连接!(不调用or则默认为使用and连接)
实例:构建一个查询用户 id 等于1,或者用户名称为“张三”的查询条件,代码如下:
1 | QueryWrapper<UserBean> wrapper = ``new` `QueryWrapper<>();` |
and
1 | and(Consumer<Param> consumer)``and(``boolean` `condition, Consumer<Param> consumer) |
参数说明:
- consumer:构造查询条件的回调接口,你需要实现 accept 方法
- condition:用于指定当前这个条件是否有效;如果为 true,则应用当前条件;如果为 false,则忽略当前条件
